Real-time News Querying: Harnessing AI for Instant Answers
Written on
Chapter 1: Introduction to AI in News Processing
In a world where news about conflicts like the Ukraine-Russia war is constantly updating, finding time to stay informed can be a challenge. Many individuals have pressing questions, such as:
- “When will my son, who is stranded in Ukraine, be evacuated?”
- “Who is assisting with the evacuation of Indian citizens?”
- “What sanctions have been placed on Russia?”
- “How much humanitarian aid has been provided to Ukraine?”
Searching through numerous articles for answers can be incredibly frustrating. Fortunately, a pre-trained AI model can swiftly provide answers from a continuous flow of news articles, sparing you the need to sift through all the information. Various Question Answering (QA) models have been developed to extract insights from text data, and I utilized the TFBertForQuestionAnswering model to create a Q&A system tailored for this scenario. Before delving into the details of developing a comprehensive Q&A system, let's explore the capabilities of this model.
Section 1.1: Understanding TFBertForQuestionAnswering
The TFBertForQuestionAnswering model is based on a transformer architecture designed for Natural Language Understanding (NLU). Sourced from Hugging Face, the model has been trained on an extensive dataset including 11,038 unpublished texts and the English Wikipedia. The data is converted to lowercase and tokenized using WordPiece, yielding a vocabulary size of 30,000. This model has been fine-tuned on the Stanford Question Answering Dataset (SQuAD), which consists of questions generated by crowd workers based on Wikipedia content. Impressively, this model achieved an f1 score of 93.15%.
To validate its performance, I tested the model on the CoQA (Conversational Question Answering) dataset, comprising over 127,000 questions derived from more than 8,000 conversations. The questions are conversational in nature, while the answers are presented in free-form text across seven different domains. My findings were remarkable, and I’d like to share a sample output to illustrate the model's accuracy.
Here’s a brief excerpt from a CoQA passage:
‘The Vatican Apostolic Library, commonly referred to as the Vatican Library, is located in Vatican City and was formally established in 1475. It is home to significant volumes dating back to the early days of the Church.’
You can explore the full passage in the original dataset. Our primary interest lies in how accurately our model responds to questions phrased in various ways, reflecting the natural language we use daily.
For instance, consider the question:
“What subjects are covered in the library?”
The dataset indicates the answer to be:
“History, law, philosophy, science, and theology.”
Now, let’s rephrase the question in four different ways:
- “What topics does the library encompass?”
- “Which subjects are present in the library's collection?”
- “What subjects can I find in the library?”
- “What topics are available in the library?”
In all cases, the model provided the same accurate response:
“History, law, philosophy, science, and theology.”
This highlights the model's capability to handle diverse phrasing effectively. Below is a screenshot from my testing to demonstrate this.
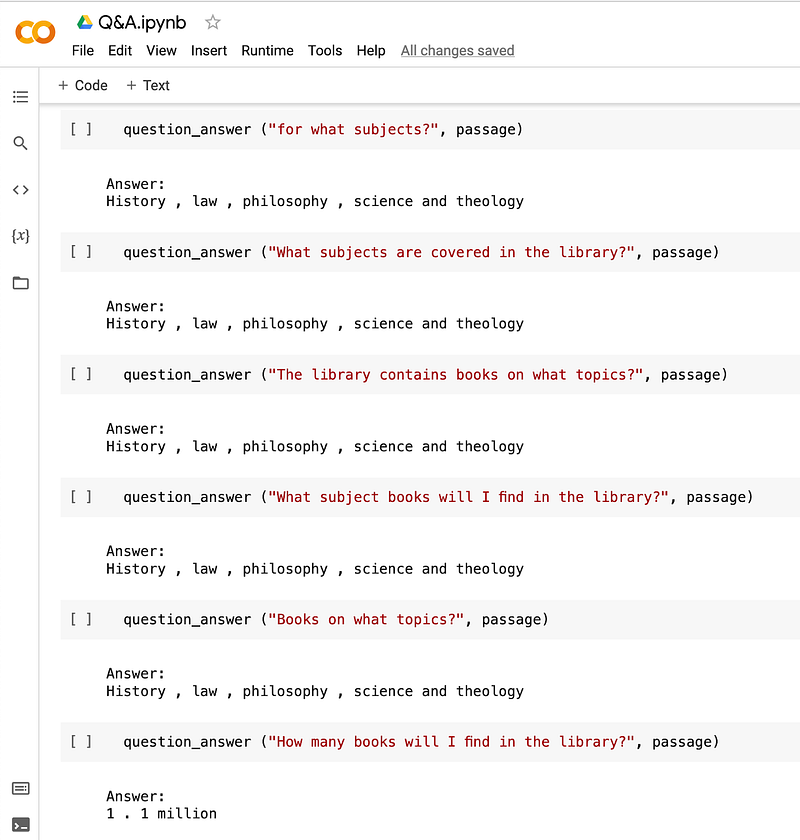
Image by author
Section 1.2: System Architecture Overview
The implementation of this system is straightforward.
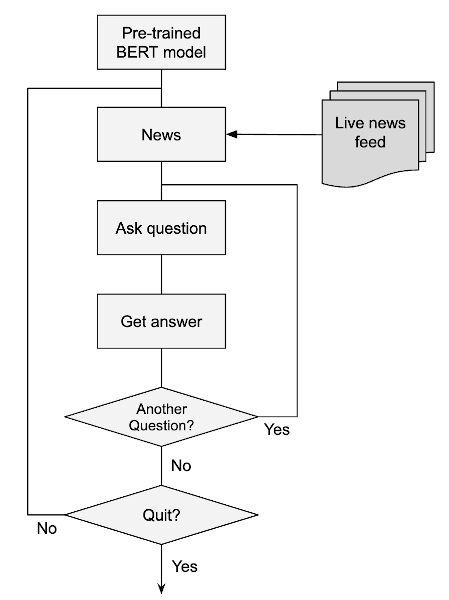
Image by author
As depicted in the diagram, we utilize the pre-trained BERT model without additional training. A simple Python script is employed to refresh our text corpus with the latest news and await user queries. The system will respond if it identifies a relevant answer within the current corpus. If it fails to find one, a message indicating "no success" is displayed. Users can opt to ask further questions or request an update to the corpus with the latest news.
Chapter 2: Project Execution
For demonstration purposes, I updated the news corpus with five pre-loaded CSV files hosted on my GitHub server. Below is a screenshot of user inquiries related to the first news item, focusing on the Ukraine-Russia situation, alongside the responses generated.
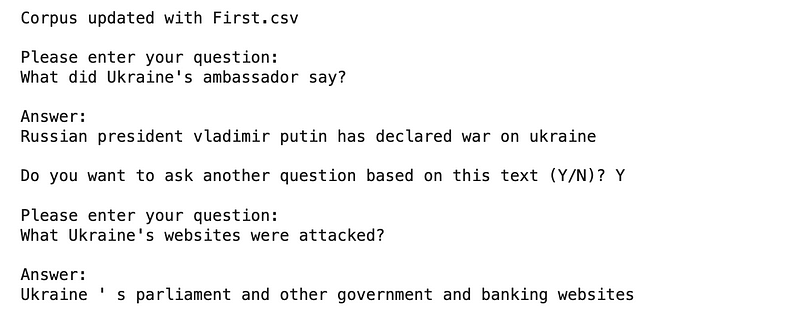
Image by author
After each inquiry, the program allows users to either pose additional questions or refresh the corpus with new information. If users choose to continue, the latest news from the second CSV file is appended to the existing corpus, ensuring that subsequent inquiries reflect the updated data. The next screenshot illustrates this process with two news items.
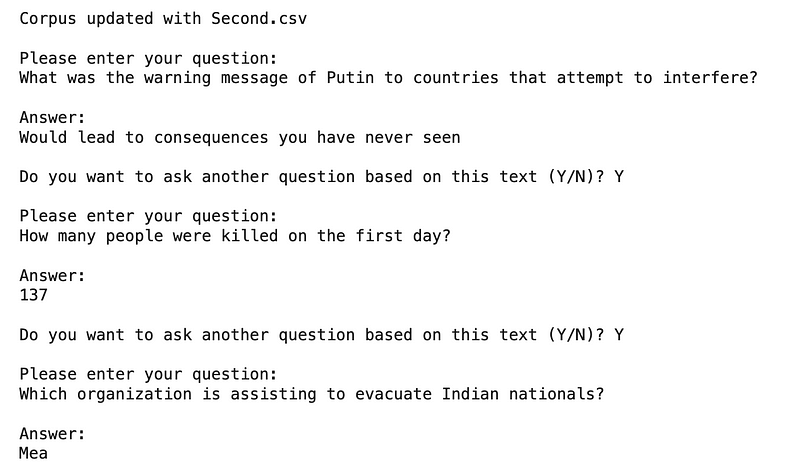
Image by author
As we add more data, the model consistently delivers accurate answers. I will now present a more intriguing scenario. After incorporating the fourth news item, I posed a specific question, as shown in the following screenshot:
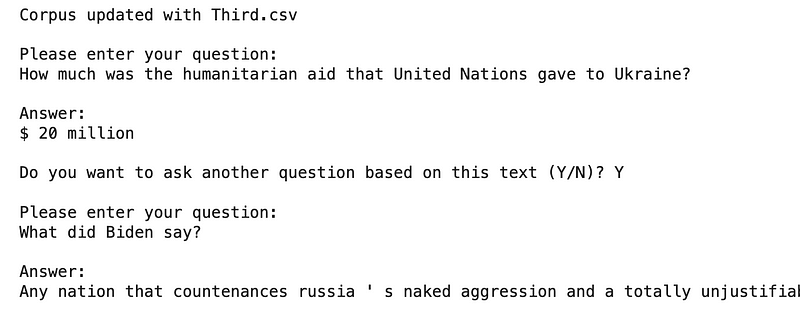
Image by author
The system indicated that the UN Security Council had called for an immediate cessation of hostilities. Upon refreshing the corpus with the latest data from the fifth CSV file and asking the same question again, here’s the outcome:

Image by author
The response revealed that Russia had attacked the Ukrainian capital. This exemplifies the model's ability to provide timely and relevant answers based on the most current information available.
You can maintain the program in a continuous loop to accept real-time user inquiries by simply substituting the CSV files with a live news feed. You can also devise your own strategy for refreshing the news corpus. I will now outline the Python code utilized in developing this model.
Section 2.1: Implementation Details
To utilize the pre-trained model, install the necessary transformers library:
!pip install transformers
Import the TFBERT model and tokenizer:
from transformers import TFBertForQuestionAnswering
from transformers import BertTokenizer
model = TFBertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
Next, I define a function to process user questions:
def question_answer(question, text):
input_ids = tokenizer(question, text, return_tensors="tf", truncation=True)
tokens = tokenizer.convert_ids_to_tokens(input_ids.input_ids[0])
output = model(input_ids)
answer_start = tf.argmax(tf.cast(output.start_logits, tf.int32), axis=1)
answer_end = tf.where(tf.equal(output.end_logits, float(tf.reduce_max(output.end_logits[0]))))[:, -1]
if answer_end >= answer_start:
answer = tokens[int(answer_start)]
for i in range(int(answer_start) + 1, int(answer_end) + 1):
if tokens[i][0:2] == "##":
answer += tokens[i][2:]else:
answer += " " + tokens[i]if answer.startswith("[CLS]"):
answer = "Unable to find the answer to your question."print("nAnswer:n{}".format(answer.capitalize()))
This function tokenizes the user query and the text corpus, processes the input, and extracts the answer based on its position within the text.
Next, a loop to manage user questions is created:
def question_answer_auto():
question = input("nPlease enter your question: n")
while True:
question_answer(question, updated_news)
flag = True
flag_N = False
while flag:
response = input("nDo you want to ask another question based on this text (Y/N)? ")
if response[0] == "Y":
question = input("nPlease enter your question: n")
flag = False
elif response[0] == "N":
print("nOK!")
flag = False
flag_N = True
if flag_N:
break
This loop allows the user to continue asking questions about the current text. When they finish, they can choose to refresh the corpus with the latest news or exit the application.
Finally, a simple loop updates the news items from pre-loaded files:
for j in files:
doc = '/content/' + j + '.csv'
updated_news = updated_news + list(pd.read_csv(doc).head(0))[0]
updated_news = re.sub("[^a-zA-Z0-9$'-., ]", "", updated_news)
print('Corpus updated with ' + j + '.csv')
question_answer_auto()
flag = True
flag_N = False
while flag:
response = input("nDo you want to quit (Y/N)? ")
if response[0] == "Y":
print("n Bye bye! n")
flag = False
flag_N = True
elif response[0] == "N":
print("n Let's continue n")
flag = False
if flag_N:
break
You can find the source code for this project in our GitHub repository.
Chapter 3: Conclusion
The Q&A system outlined here demonstrates the capabilities of the TF BERT pre-trained model. I tested it on various text corpora, manipulating the phrasing of questions, and consistently received excellent results. The model effectively provides extractive summaries of the text. Given the 512-token limit, the model may need to be reloaded as the text corpus expands.
This code serves as a foundation for a robust application capable of answering natural language questions across a multitude of topics. If the answer is not present, the system will indicate a lack of success. However, if the answer exists within the text corpus, it will extract it for you, eliminating the need to read through the entire corpus.
Credits
George Saavedra — Program development