Maximizing Your Machine Learning Model's Resilience and Performance
Written on
Introduction to Resilience in Machine Learning
In the realm of data science, the expectations from clients and businesses are consistently high. Consequently, ensuring that solutions are both resilient and readily available becomes essential. As data scientists, we recognize the significance of not only crafting effective models but also ensuring their dependability when faced with challenges. The Model as a Service (MaaS) concept has gained traction, providing pre-built models for various tasks such as natural language processing, computer vision, and recommendation systems. This approach streamlines the model development process, saving time and resources for data scientists.
A key consideration is the capacity of a service or API to manage traffic effectively, which can only be evaluated through stress testing. The insights gained from such tests help architects and data scientists determine the necessary infrastructure setup. This blog delves into the nuances of stress testing for machine learning models.
Creating a Basic Web API with FastAPI
In this section, we will illustrate the fundamental implementation of FastAPI, a web API designed to produce specific outputs based on given inputs.
- Import the necessary libraries.
- Instantiate an app object.
- Set up a route using @app.get().
- Write a driver function that specifies the host and port numbers.
from fastapi import FastAPI
import uvicorn
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Built with FastAPI"}
if __name__ == '__main__':
uvicorn.run(app, host='127.0.0.1', port=8000)
Once this code is executed, you can visit the URL: http://localhost:8000 to see the output, which should read ‘Built with FastAPI’.
Integrating a Machine Learning Model into FastAPI
Now, let’s explore how to incorporate a Python machine learning model into an API using the Breast Cancer Wisconsin (Diagnostic) dataset. The objective is to predict whether tumors are benign or malignant. We will utilize the Postman client for testing and VSCode for editing.
Step 1: Building the Classification Model
We’ll create a straightforward classification model following the standard steps: loading the data, splitting it into training and testing sets, and saving the model in pickle format. The detailed model building process will not be covered here, as our focus is on load testing.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import pickle
import os
# Load configuration and dataset
CONFIG_PATH = "../Configs"
filename = "../../Data/breast-cancer-wisconsin.csv"
data = pd.read_csv(filename)
data = data.replace('?', -99999)
data = data.drop(config["drop_columns"], axis=1)
X = np.array(data.drop(config["target_name"], 1))
y = np.array(data[config["target_name"]])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=config["test_size"], random_state=config["random_state"])
classifier = KNeighborsClassifier(n_neighbors=config["n_neighbors"])
classifier.fit(X_train, y_train)
result = classifier.score(X_test, y_test)
print("Accuracy score is {:.1f}".format(result))
pickle.dump(classifier, open('../../FastAPI/Models/KNN_model.pkl', 'wb'))
For the complete code, refer to our GitHub repository.
Step 2: Building the API
We will build upon the basic example discussed earlier.
- Import the required libraries.
- Load the saved KNN model and create a routing function to return JSON responses.
@app.get("/")
async def root():
return {"message": "Hello World"}
model = pickle.load(open('../Models/KNN_model.pkl', 'rb'))
@app.post('/predict')
def pred(body: dict):
data = body
varList = list(data.values())
prediction = model.predict([varList])
output = prediction[0]
return {'The prediction is ': output}
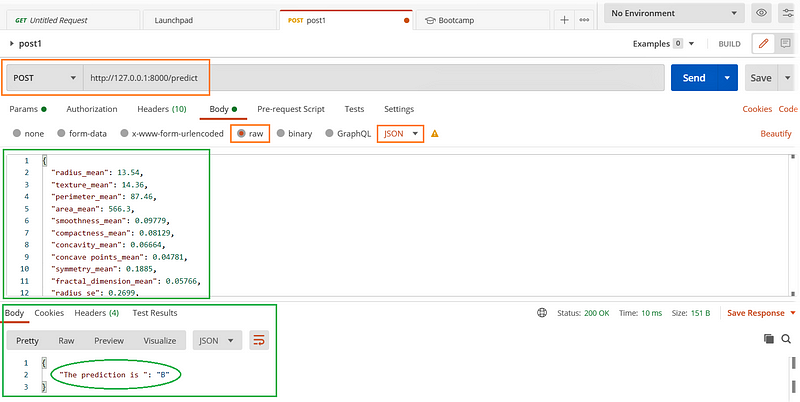
Step 3: Testing with Postman
To validate our API, we will use Postman, which offers a more user-friendly interface for testing.
- Run the server.py file.
- Open Postman, fill in the necessary details, and hit the send button to observe the results.
Conducting a Stress Test with Locust
For load testing, we will utilize the Locust library, which can be easily installed using:
pip install locust
Let’s create a perf.py file with the following code:
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 3)
@task(1)
def testFlask(self):
load = {
"radius_mean": 13.54,
"texture_mean": 14.36,
# other parameters...
}
myheaders = {'Content-Type': 'application/json', 'Accept': 'application/json'}
self.client.post("/predict", json=load, headers=myheaders)
To start Locust, navigate to the directory where perf.py is located and execute:
locust -f perf.py
Once Locust is running, visit http://localhost:8089 to access the web interface.
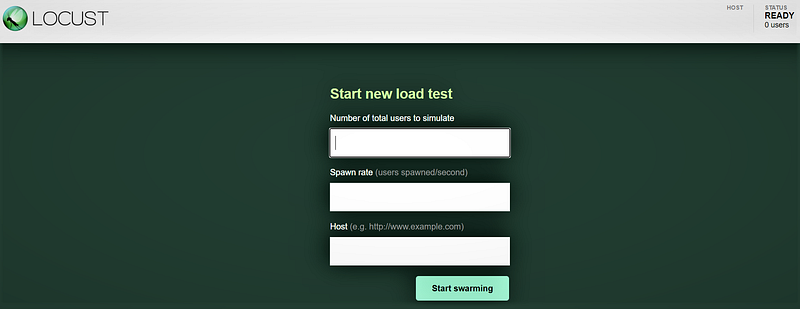
You can simulate 100 users, adjust the spawn rate, and specify the host as http://127.0.0.1:8000, where our API is hosted.
Importance of Stress Testing
Stress testing is vital to identify potential weaknesses in models, ensuring they can withstand high workloads and unexpected scenarios. This process not only enhances reliability but also highlights areas for improvement, ultimately boosting performance.
Conclusion
In summary, we have explored how to create a machine learning model, test it using FastAPI, and execute a load test with 100 simulated users. Adhering to business-level SLAs, such as maintaining response time thresholds, is critical to avoid financial repercussions or customer churn. Stress tests allow for the identification of peak loads and potential failure points, enabling proactive measures such as scaling infrastructure.
We hope you found this article insightful and useful.
Additional Resources
If you appreciated this blog, consider exploring more topics in data science and Python:
- How To Build Explainer Dashboard In Python
- Improving Python Code Readability With Type Hinting and Mypy
- Automate And Standardize Testing With Tox In Python
- Sensitivity Analysis Using Python
FAQs
Q1. What is stress testing in Python data science?
A1: Stress testing is a rigorous assessment of a data science solution's robustness and reliability under extreme conditions.
Q2. Why is stress testing important for data science projects?
A2: It helps identify weaknesses, ensuring models can handle unexpected data and high workloads, thus improving reliability.
Q3. How can I perform stress testing on my solution?
A3: Simulate extreme scenarios, use larger datasets, introduce noisy data, and evaluate responses to edge cases.
Q4. Can stress testing enhance my solution's performance?
A4: Yes, it identifies areas for improvement, enhancing overall performance and resilience.
References
- FastAPI framework: high performance, easy to learn, ready for production.