Innovative Pretraining Techniques for Self-Attention Networks
Written on
Chapter 1: Overview of Cloze-Driven Pretraining
This paper presents a novel approach to pretraining bidirectional transformers, aimed at boosting performance across various language comprehension tasks. The primary achievements include substantial improvements on the GLUE benchmark and new state-of-the-art results in Named Entity Recognition (NER) and constituency parsing.
Prerequisites
Before delving into the details, it's essential to understand a couple of concepts:
- Cloze-Reading: This task involves filling in missing words in a sentence. For instance, in "This is a _____ paper," the goal is to predict "research" from the surrounding context.
- Transformers: If you need a refresher, refer to this informative blog on transformers.
Introduction
The authors argue that earlier bidirectional training utilized separate loss functions for each direction. This paper proposes a unified pretraining methodology that simultaneously trains both directions. The resulting bidirectional transformer is designed to predict every token based on cloze-style training, wherein the model predicts a central word from both left-to-right and right-to-left contexts.
The model calculates both forward and backward states utilizing a masked self-attention architecture.
The Two Tower Model
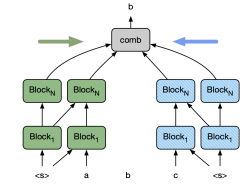
The cloze model establishes a probability distribution ( p(t_i | t_1, ldots, t_{i-1}, t_{i+1}, ldots, t_n) ) for a sentence containing ( n ) tokens. It comprises two self-attentional towers, with the forward tower operating left-to-right and the backward tower functioning in the opposite direction. To predict a token, the model amalgamates the representations from both towers, ensuring neither contains information about the target token.
The forward tower generates the representation ( F_{il} ) for token ( i ) at layer ( l ) based on the prior layer's forward representations ( F_{l-1} ) through self-attention, while the backward tower computes ( B_{il} ) from the reverse direction ( B_{l-1} ).
Block Structure
Each block consists of two sub-blocks:
- The first is a multi-head self-attention block with ( H = 16 ).
- The second is a Feed Forward Network (FFN).
Position information is encoded using fixed sinusoidal position embeddings (similar to transformers). Additionally, a character-based CNN is employed for token encoding, where words are decomposed into characters. The character embeddings are formed using Conv1D layers of varying filter sizes, followed by max pooling and a highway network to produce the final word embedding.
Notably, layer normalization is applied before the two sub-blocks, enhancing training effectiveness. The input embeddings are shared across both models.
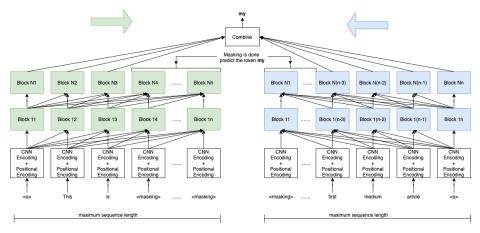
Combination of Outputs
The outputs from both towers are processed through a self-attention module, followed by an FFN and a softmax activation corresponding to the vocabulary size ( V ). When predicting token ( i ), the attention module's input includes forward states ( F_{L1} ldots F_{Li-1} ) and backward states ( B_{i+1} ldots B_n ), where ( n ) represents the sequence length and ( L ) the number of layers. The attention query for token ( i ) integrates ( F_{Li-1} ) and ( B_{Li+1} ). For the base model, these representations are summed, while larger models concatenate them.
Fine-Tuning Adjustments
During fine-tuning, several modifications are applied:
- All tokens from the input sentences are processed through both towers.
- The softmax layer is removed, allowing access to the model's output via the boundary token.
- When processing two sentences, a special token separates them.
- It is advantageous to remove the masking of the current token in the final layer that pools the outputs from both towers.
Datasets Utilized
The following datasets were employed:
- Common Crawl: 9 billion tokens
- News Crawls: 4.5 billion words
- Book Corpus + Wikipedia: 800 million words, with an additional 2.5 billion words from English Wikipedia (similar to BERT).

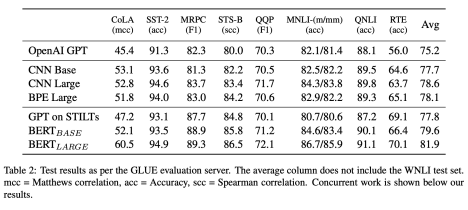
Results and Evaluation
The results are compelling:
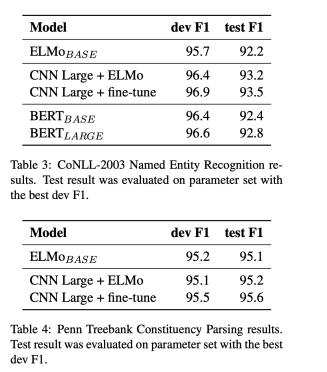
For evaluating NER, the CoNLL-2003 dataset along with the Penn Treebank was utilized.
Conclusion and Further Reading
For additional insights, refer to the original paper and related articles.
Stay connected by following me on LinkedIn (Aziz Belaweid) or GitHub!
Chapter 2: Video Insights
The video titled "[Paper Review] Latent Retrieval for Weakly Supervised Open Domain Question Answering" offers in-depth explanations and discussions based on the paper's concepts, enhancing your understanding of the material presented.